内部资料,请扫码登录
工作流功能以dev分支为准,当前功能正在快速迭代中
# 工作流功能介绍
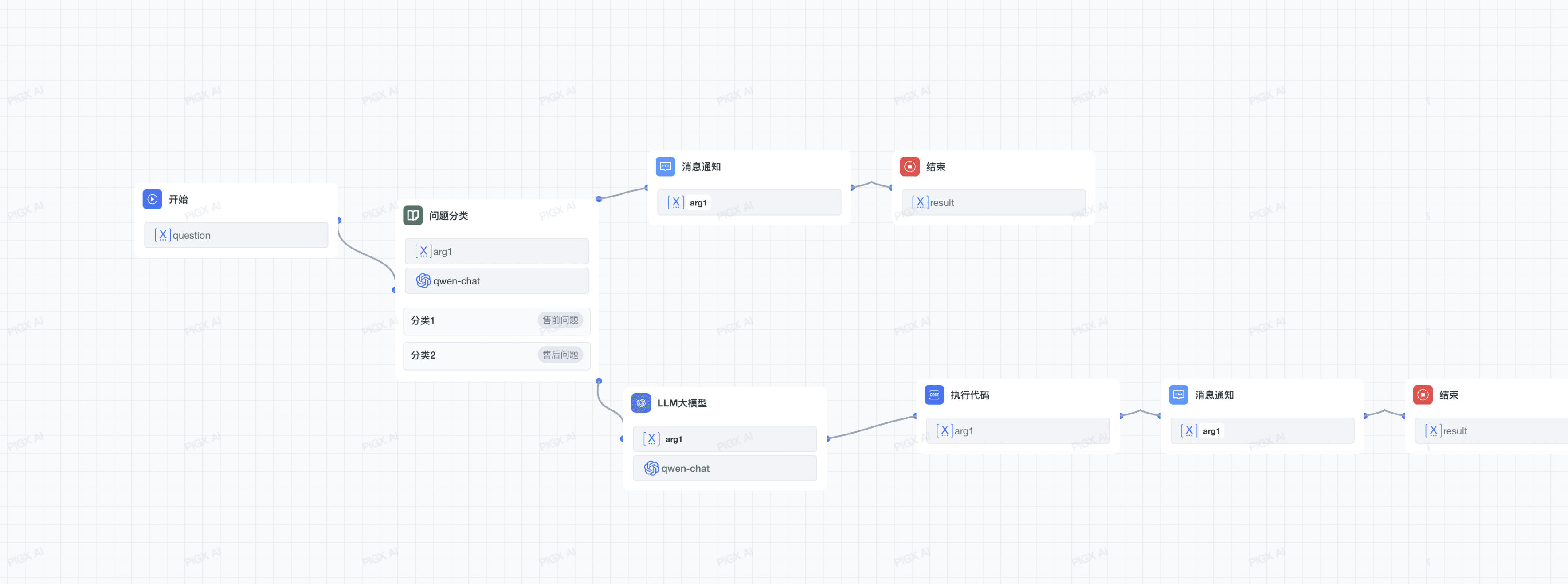
工作流是 PIG AI 平台的核心功能之一,通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
# 1. 关键概念
# 1.1 节点
节点是工作流的关键构成,通过连接不同功能的节点,执行工作流的一系列操作。工作流的核心节点包括开始节点、结束节点、LLM节点、条件分支节点等,每个节点都有特定的功能和配置选项。
# 1.2 变量
变量用于串联工作流内前后节点的输入与输出,实现流程中的复杂处理逻辑,包含系统变量、环境变量和会话变量。变量作为一种动态数据容器,能够存储和传递不固定的内容,在不同的节点内被相互引用,实现信息在节点间的灵活通信。
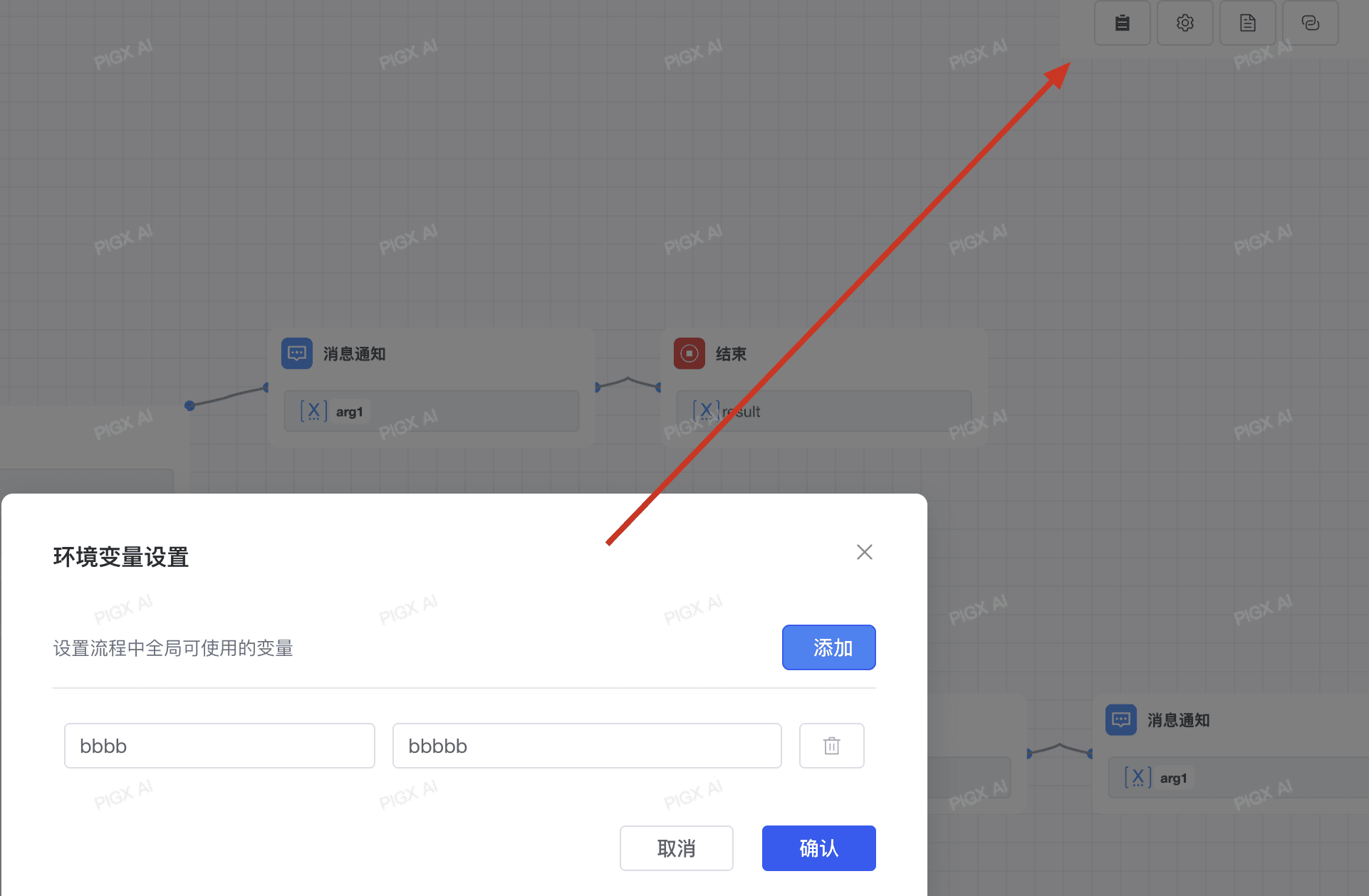
# 1.3 环境变量
环境变量用于保护工作流内所涉及的敏感信息,例如运行工作流时所涉及的 API 密钥、数据库密码等。它们被存储在工作流程中,而不是代码中,以便在不同环境中共享。
环境变量拥有以下特性:
- 环境变量可在大部分节点内全局引用
- 环境变量命名不可重复
- 环境变量为只读变量,不可写入
# 2. 工作流节点类型
# 2.1 开始节点
开始节点是 Chatflow / Workflow 应用中的关键预设节点。它提供了基本的初始信息,根据用户输入的参数以支持应用和后续工作流节点的正常流程。
在开始节点的设置页面,你会找到:"变量列表"。用户调用发布的智能体编排的时候需要按照开始节点要求进行入参。
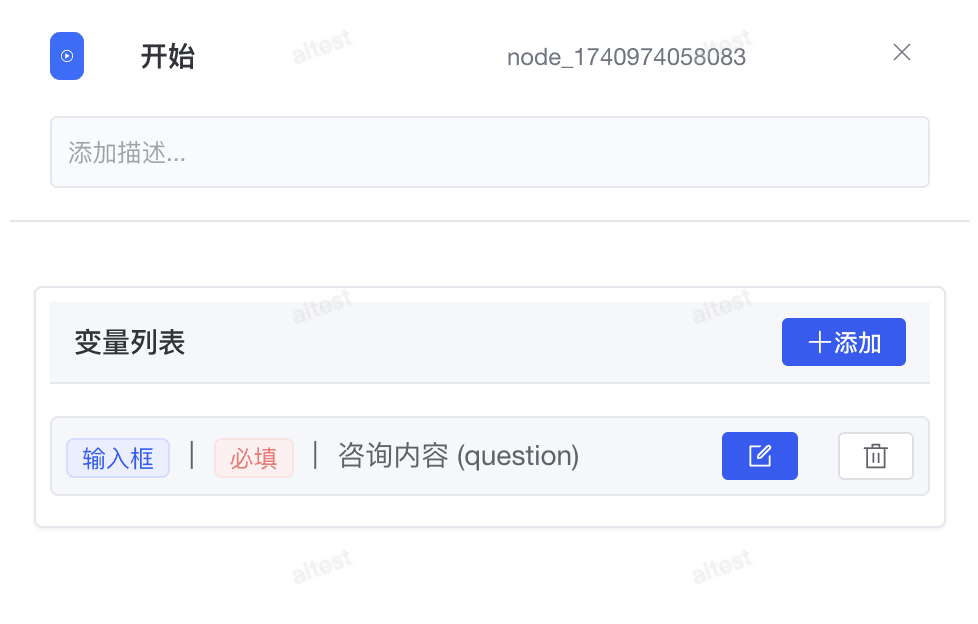
# 2.1.1 输入字段
输入字段由应用开发者配置,用于提示用户提供额外信息。例如,在周报应用中,可能需要用户提供姓名、工作日期范围和工作详情等背景信息,这些初步信息有助于 LLM 生成更高质量的回复。
# 2.2 问题分类节点
问题分类节点通过定义分类描述,使 LLM 能够根据用户输入选择与之相匹配的分类。这个节点特别适用于需要根据用户问题类型进行不同处理路径的场景。
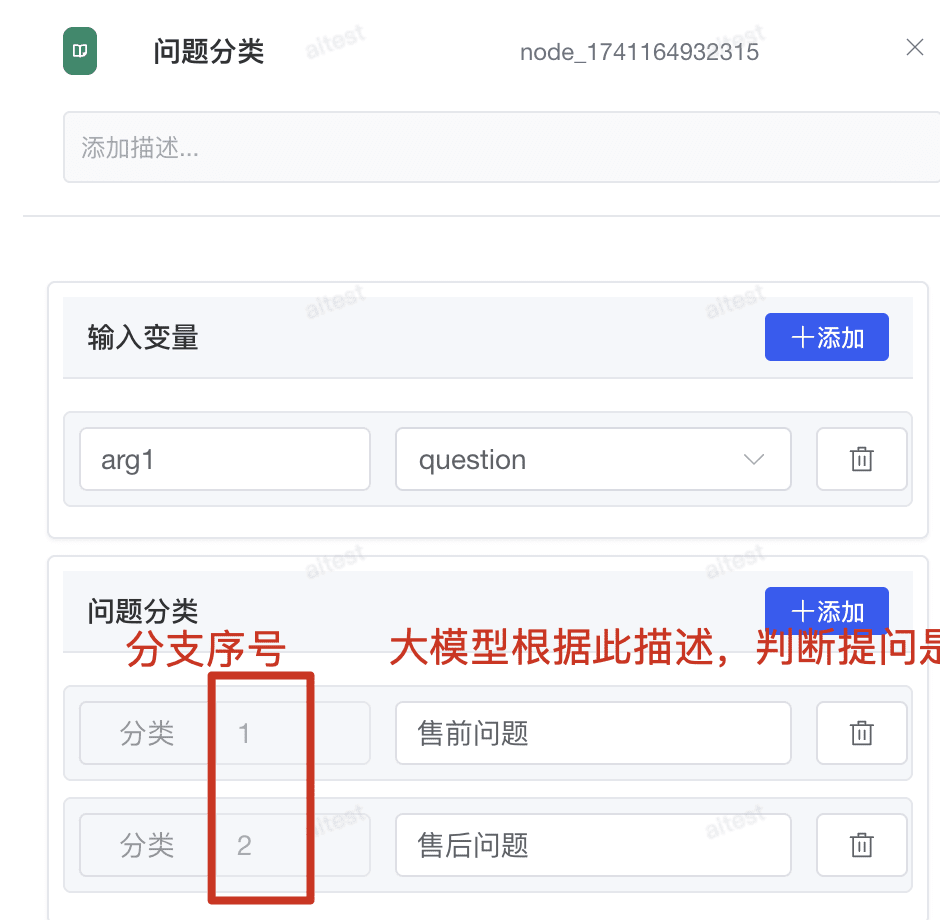
# 2.2.1 节点参数
- 输入变量:固定 arg1,对应选择上一节点传递的参数
- 问题分类:分类序号,分类描述(非常重要);非常重要,大模型根据分类描述来判断问题分类节点走哪个需要的分支
# 2.2.2 节点功能
问题分类节点允许你定义多个分类,每个分类包含:
- 分类名称:用于标识该分类的唯一名称
- 分类描述:详细说明该分类所涵盖的问题类型和特征
- 示例问题:提供该分类的典型问题示例,帮助 LLM 更准确地识别
当用户提问时,LLM 会分析问题内容,并将其归类到最匹配的分类中,然后工作流可以根据分类结果执行不同的处理路径。
# 2.2.3 使用场景
问题分类节点适用于以下场景:
- 客户服务:将用户问题分类为产品咨询、技术支持、投诉建议等
- 内容推荐:根据用户兴趣分类,提供个性化内容推荐
- 多功能助手:根据用户意图分类,执行不同的功能模块
# 2.3 分支节点
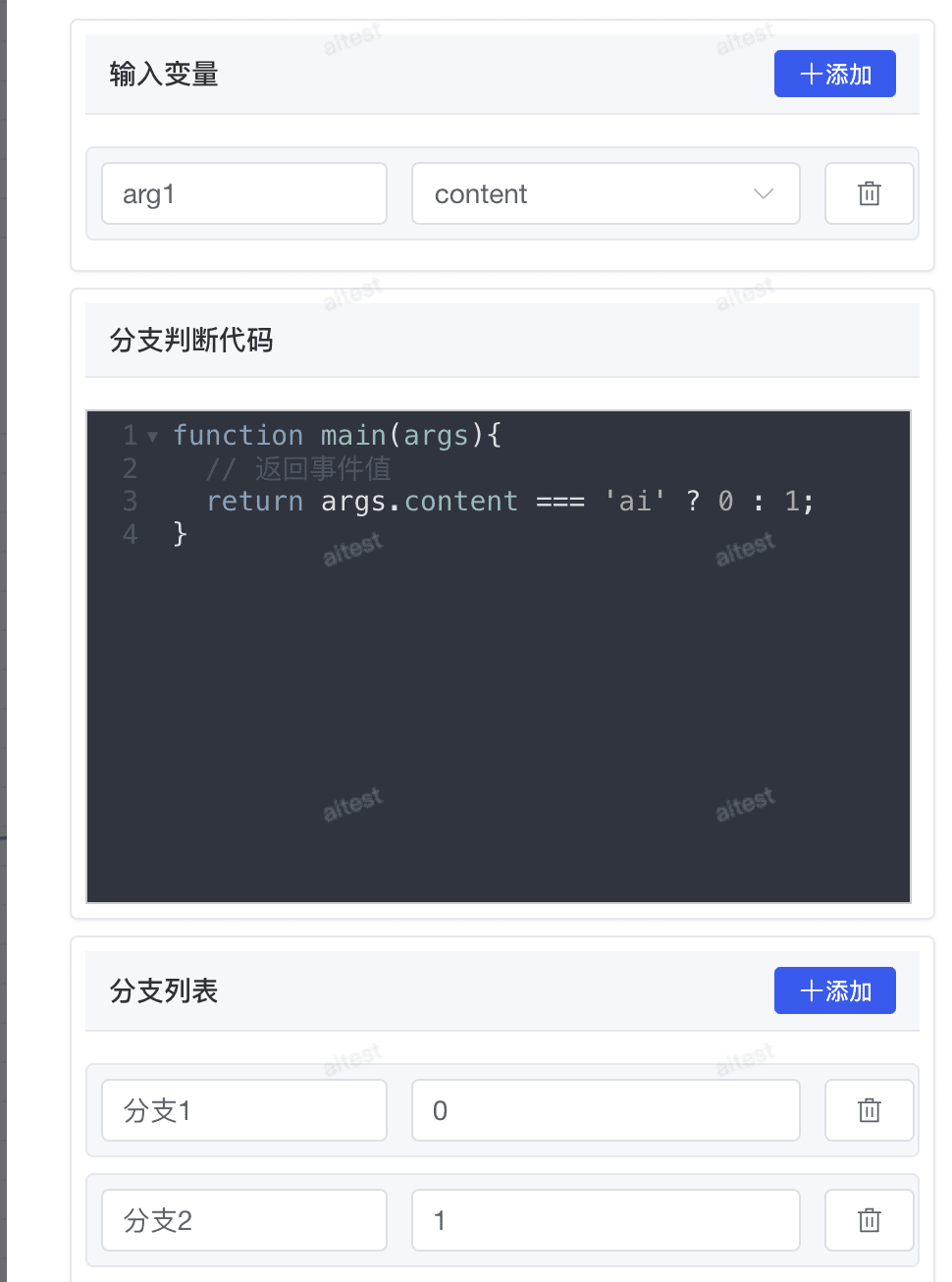
条件分支节点允许你根据 if/else/elif 条件将工作流拆分成多个分支,实现复杂的逻辑控制。
通过条件判断代码动态控制工作流分支走向,根据输入参数值返回对应的分支索引。以下示例演示如何根据用户输入参数判断执行路径:
function main(args) {
// 条件判断:当输入参数等于 'ai' 时返回分支索引 0,否则返回分支索引 1
// Conditional check: Return branch index 0 when input equals 'ai', otherwise branch index 1
return args.content === 'ai' ? 0 : 1;
}
# 2.4 代码执行节点
代码执行节点支持运行 JS 代码以在工作流程中执行数据转换等自定义逻辑。它可以简化你的工作流程,适用于算术运算、JSON 转换、文本处理等情景。
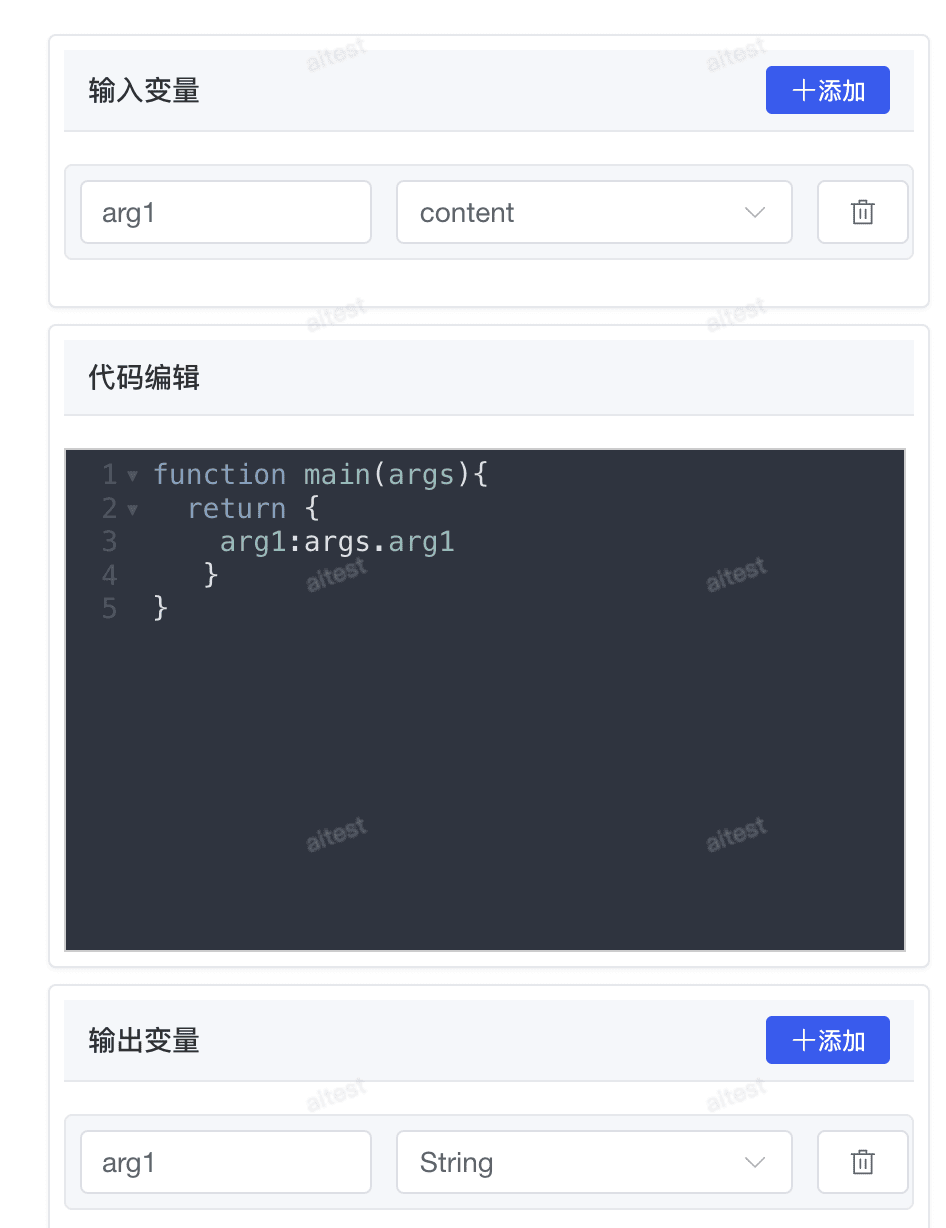
// 这里返回值必须是 map ,才能被下游感知
function main(args){
// 可以通过 args.arg1 的形式获取上文参数
return {
arg1:args.arg1,
arg2:args.arg2
}
}
# 2.5 LLM节点
LLM节点是工作流中的核心组件,用于调用大语言模型执行各种智能任务。通过简单的配置方式,你可以轻松地将大模型能力集成到工作流中,无需编写复杂代码。
# 2.5.1 节点功能
LLM节点支持以下核心功能:
- 模型选择:可选择系统配置的各种大语言模型,如 qwen-max、GPT-4 等
- 系统提示词:设置模型的基础行为指导和角色定义
- 用户提示词:构建具体的任务指令,可引用工作流变量
- 温度参数:调整模型输出的创造性和随机性
- 最大输出:控制模型生成内容的长度限制
# 2.5.2 使用场景
LLM节点适用于多种场景:
- 内容生成:撰写文章、报告、摘要等各类文本内容
- 知识问答:回答用户问题,提供专业领域知识
- 数据分析:解释数据趋势,生成数据分析报告
- 决策辅助:基于输入信息提供建议和决策支持
# 2.5.3 变量引用
在提示词中,你可以通过 ${变量名} 的方式引用工作流中的变量,实现动态提示词构建:
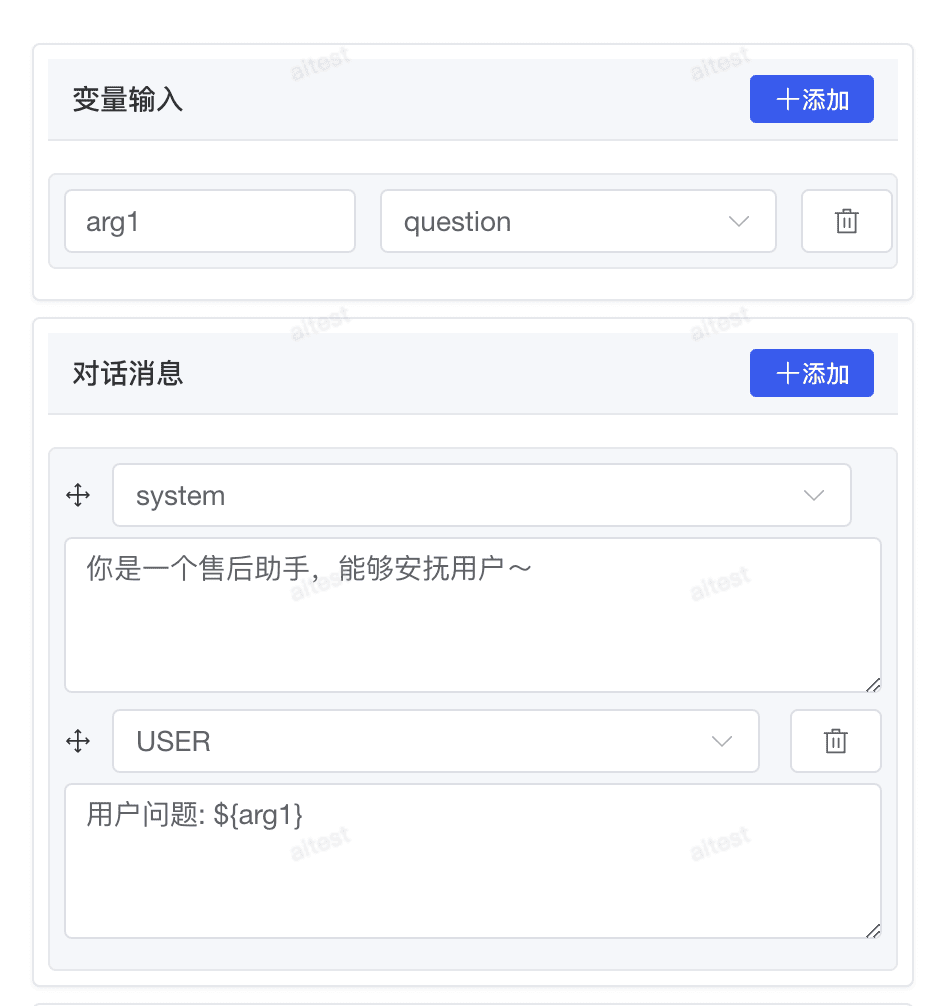
# 2.6 数据库节点
数据库操作节点允许工作流与数据库进行交互,执行查询、插入、更新和删除等操作。这个节点特别适用于需要持久化存储数据或从数据库检索信息的场景。
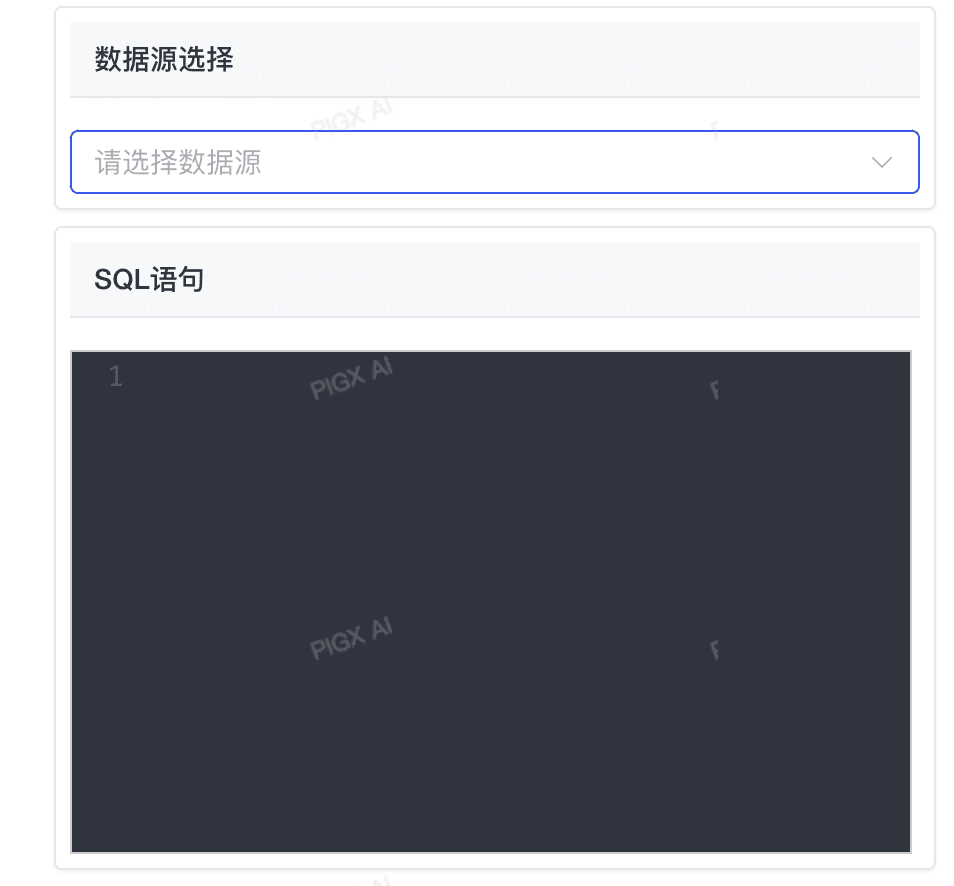
# 2.6.1 节点功能
这里可以直接选择开发平台维护的数据源,然后针对目标数据源写SQL:
直接 SQL 查询:允许你编写 SQL 语句直接操作数据库
# 可以通过 ${} 获取变量输入
SELECT * FROM users WHERE age > ${arg1}
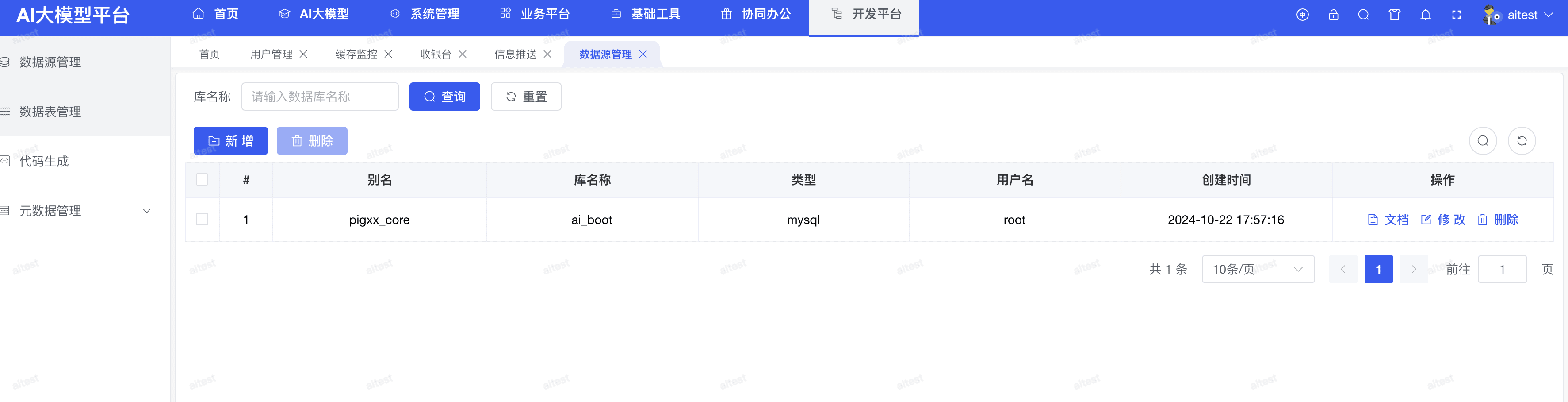
# 2.6.2 数据源维护
- 数据源列表:通过开发平台平台 > 新增数据源进行维护
# 2.7 HTTP 请求节点
HTTP 请求节点允许通过 HTTP 协议发送服务器请求,适用于获取外部检索结果、webhook、生成图片等情景。
# 2.7.1 节点功能
HTTP 请求节点支持以下功能:
- 请求类型:支持 GET、POST、HEAD、PATCH、PUT、DELETE 等 HTTP 方法
- 鉴权类型:支持无鉴权、API-Key 基础、API-Key Bearer、API-Key 自定义等多种鉴权方式
- 请求头:可设置自定义 HTTP 请求头
- 请求参数:支持 URL 参数设置
- 请求体:支持 none、form-data、x-www-form-urlencoded、raw text、JSON 等多种格式
# 2.8 消息通知节点
消息通知节点允许工作流将处理结果通过多种渠道发送通知,支持与企业常用的通信工具集成,实现自动化的消息推送。
# 2.8.1 节点功能
消息通知节点支持以下功能:
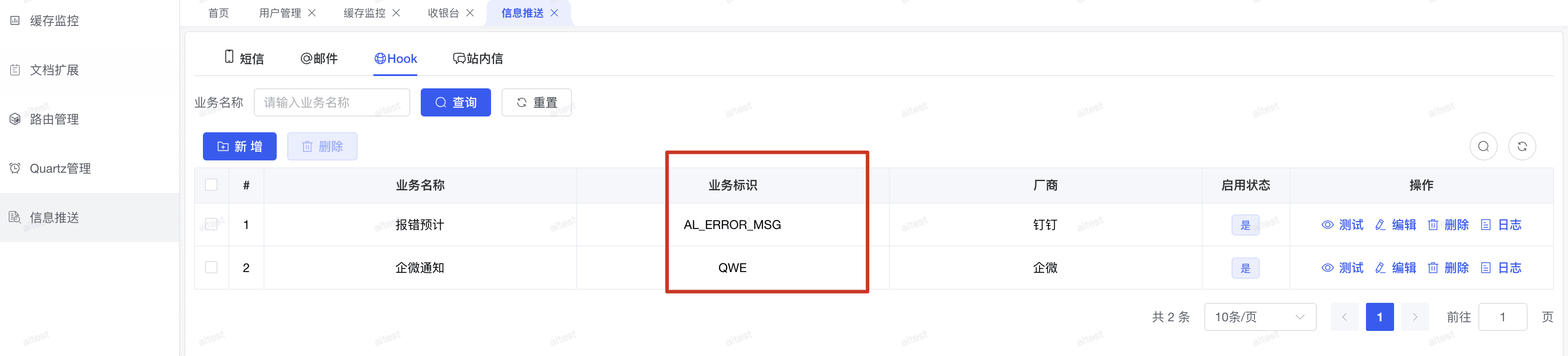
- 通知渠道:支持通过 PIGX 的消息推送模块进行结果推送
- 集成方式:支持 webhook 方式接入钉钉、企业微信等企业通讯工具
- 变量替换:可在消息内容中引用工作流变量,实现动态内容推送
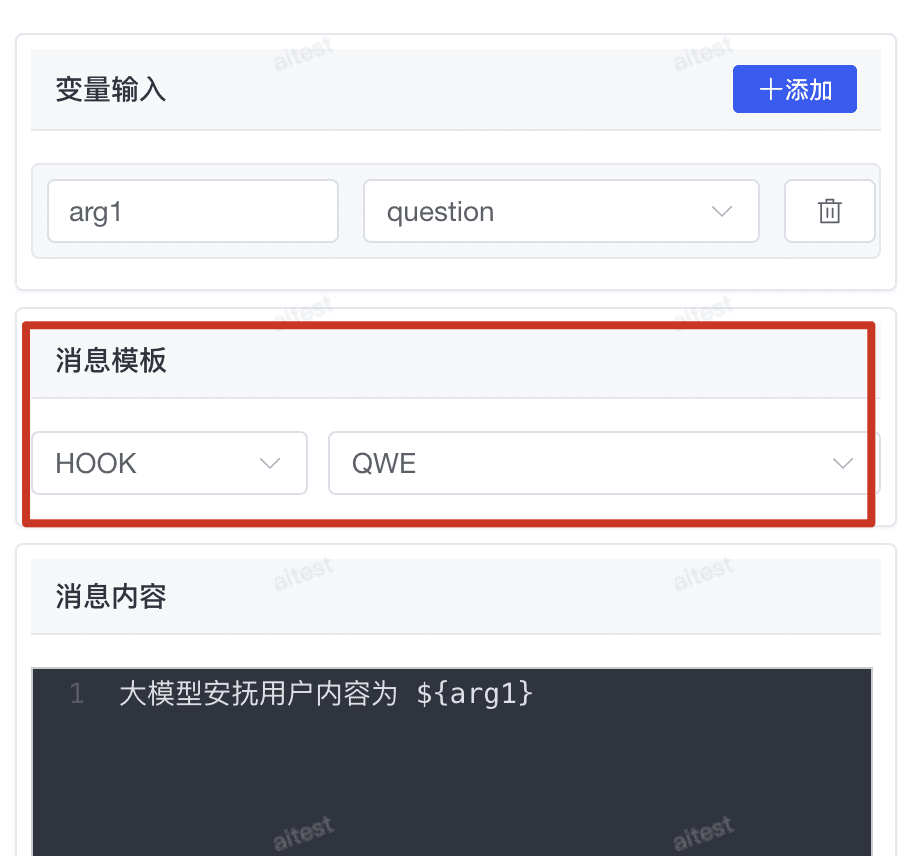
# 2.8.2 推送渠道维护
# 2.9 知识库节点
知识库节点允许工作流直接查询已配置的知识库,实现对特定领域知识的检索和利用,是实现 RAG(检索增强生成)的关键组件。
# 2.9.1 节点功能
知识库节点支持以下功能:
- 知识库选择:可选择系统中已配置的任意知识库
- 提示词设置:支持自定义提示词,引导大模型如何利用检索到的知识
- 参数动态填充:通过
${}语法在提示词中动态填充工作流变量
# 2.9.2 使用注意事项
- 知识库节点为同步查询模式,如果知识库的大模型响应较慢,可能导致超时
- 对于第三方调用知识库的场景,建议适当增加超时时间设置
- 可以结合条件节点,根据知识库查询结果决定后续流程走向
# 2.10 结束节点
结束节点定义一个 workflow 流程结束的最终输出内容。它是工作流的终点,用于汇总处理结果并返回给用户或其他系统。
# 3. 应用发布 (API)
对话型应用支持发布为:
- 直接运行
- 访问 API - 通过标准化接口供外部其他应用系统调用
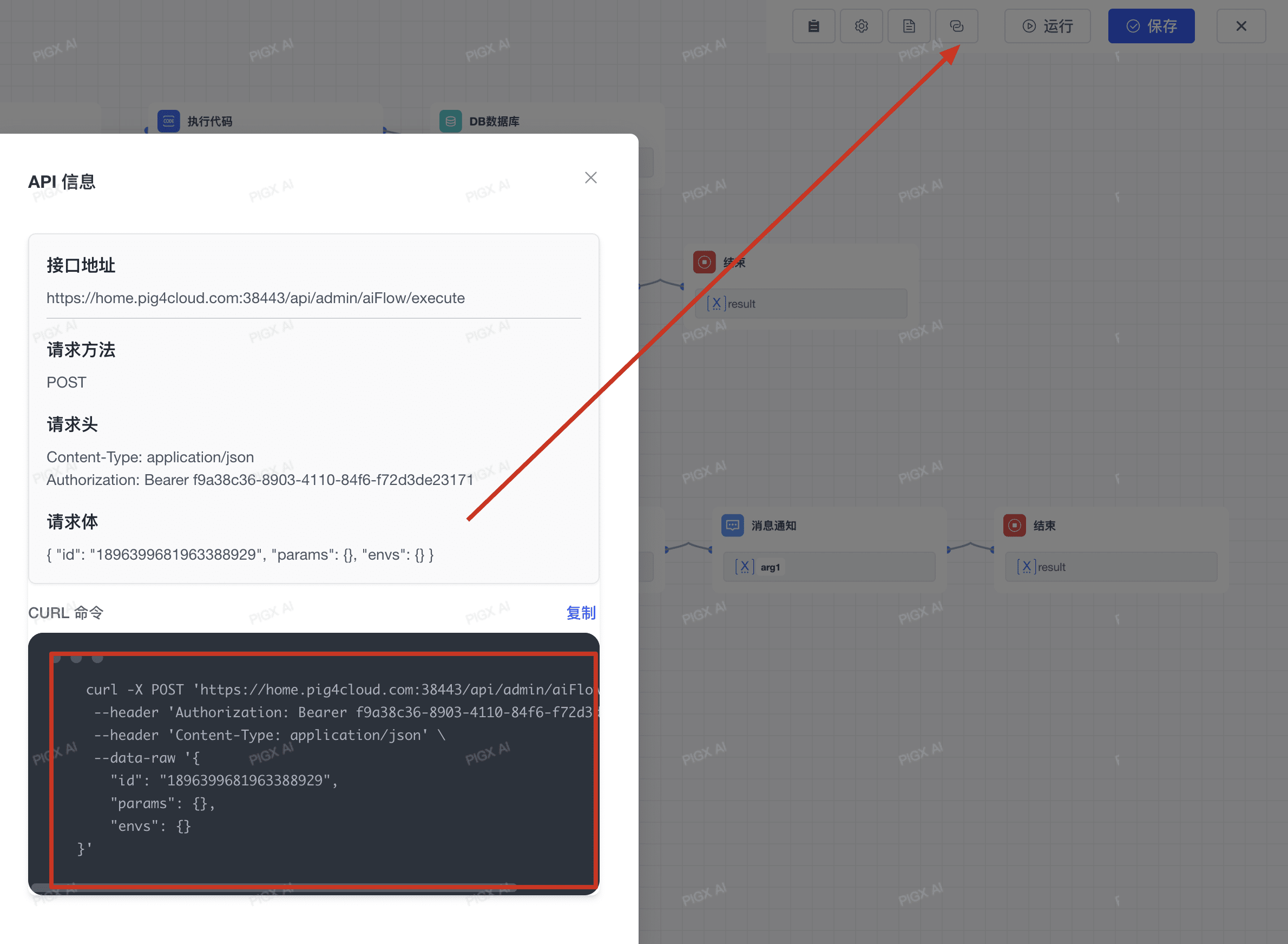
# 3.1 请求参数描述
| 参数名称 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | string | 是 | 应用ID |
| params | object | 是 | 应用输入参数 【对应开始节点的参数要求】 |
| envs | object | 否 | 额外环境变量参数 |
# 3.2 响应参数描述
| 参数名称 | 类型 | 说明 |
|---|---|---|
| code | number | 状态码,0表示成功 |
| msg | string | 状态消息,成功时为null |
| data | object | 返回数据对象 |
| data.nodes | array | 节点信息数组 |
| data.variables | object | 变量信息 |
| data.result | object | 结果信息 【对应结束节点参数配置】 |
| ok | boolean | 请求是否成功 |